
원문은 리턴제로 Github 에서 확인할 수 있습니다.
A curated list of Korean speech recognition resources for developers, including the error rate (Character Error Rate) of Speech Recognition API on public datasets.
한국어 음성인식을 사용해볼 수 있는 개발자 사이트의 API로 AI-Hub에서 공개한 다양한 테스트셋의 에러율(Character Error Rate) 을 음성인식 API별로 측정한 리포지토리입니다. 본 리포지토리는 다음과 같은 내용을 다루고 있습니다.
- Return Zero(리턴제로), Google, OpenAI Whisper, ETRI, Naver 등 다양한 음성인식 API를 사용하여 AI Hub 테스트셋에 대한 에러율(Character Error Rate) 측정
- 한국어 음성인식 평가 방법에 대한 소개
Contents
- 한국어 음성인식 API - API List
- 한국어 데이터셋 - 사용한 테스트 데이터셋
- 음성인식 API 별 에러율 - 각 API 별 에러율 측정 결과
- 한국어 음성인식 - 한국어 음성인식에 대한 간략한 소개와 이 레포를 만들게 된 배경에 대해 설명
- 왜 CER로 계산하나요? (Character Error Rate) - 한국어 음성인식 메트릭 설명
- 전사 데이터 정규화(Normalization) - 전사 데이터의 normalization 설명
- 한국어 데이터셋에 덧붙여 - 각 테스트 데이터셋 별 설명
한국어 음성인식 API
API로 음성인식을 바로 사용해 볼 수 있는 개발자 사이트입니다. 별도의 승인 절차나 영업 컨택 없이 바로 사용해볼 수 있는 사이트를 주로 나열해두었습니다.
- OpenAI의 Whisper
- Google의 Cloud Speech-to-text v2
- 한국전자통신연구원 ETRI의 공공 인공지능오픈 API
- Naver Cloud의 Clova Speech
- Return Zero의 VITO Speech
아래는 이번에 다루지 못했지만 크레딧이 주어지는 경우 추후에 테스트 해볼 예정입니다.
한국어 데이터셋
- 주요 영역별 회의 음성 - 시사토론, 독서모임, 온라인회의, 방송에서의 자연스러운 환경과 잡음이 결합된 회의 형태의 발성 데이터
- 회의 음성 - TV, 라디오의 토론, 토크, 뉴스 등의 음성 콘텐츠에서 추출한 데이터
- 상담 음성 - 교육, 금융, 통신판매 도메인에 대한 콜센터 가상 시나리오 데이터
- 저음질 전화망 음성 - 실제 상담 환경에서 발생하는 다양한 잡음을 포함한 저음질 전화망 데이터
- 한국어 강의 음성 - EBS의 교육영상을 기반으로 만든 데이터
- 한국어 음성 (KsponSpeech) - 두 사람이 다양한 주제로 자유롭게 대화하는 음성을 스튜디오에서 녹음한 데이터로 테스트 세트가 2개로 나뉘어 구성됩니다(eval clean, eval other)
음성인식 API 별 에러율
평가된 각 음성인식 API의 세부 정보와 CER 측정 결과입니다.
비용과 시간 관계상 테스트셋 별로 3000개의 문장을 샘플링하여 테스트를 진행하였습니다.
테이블 내의 숫자는 작을수록 에러가 적다는 의미입니다.
리턴제로의 엔진과 리턴제로 Whisper 엔진이 평균 에러율 8% 밑으로 1,2위를 차지하고 있으며 그 뒤를 Naver Clova 가 따라오고 있습니다.
| API \ 데이터셋 | Avg. CER(%) | 주요 영역별 회의 | 회의 | 상담 | 저음질 전화망 |
한국어 강의 |
KsponSpeech eval clean |
KsponSpeech eval other |
|---|---|---|---|---|---|---|---|---|
| OpenAI Whisper | 11.39 | 10.49 | 10.16 | 7.51 | 17.27 | 10.89 | 12.06 | 11.34 |
| Google api v2 |
11.50 | N/A | 11.62 | 8.37 | 14.11 | 11.48 | 11.82 | 11.59 |
| ETRI | 10.19 | 9.95 | 10.56 | 8.36 | 15.46 | 9.89 | 9.99 | 7.15 |
| Naver ClovaSpeech | 9.52 | 7.88 | 8.53 | 5.89 | 9.09 | 13.71 | 10.66 | 10.86 |
| 리턴제로 | 6.18 | 6.78 | 7.27 | 3.56 | 4.66 | 7.76 | 6.61 | 6.64 |
| 리턴제로 Whisper | 7.79 | 6.43 | 8.85 | 5.44 | 5.52 | 8.68 | 9.74 | 9.86 |
Awesome 한국어 음성인식을 소개하면서
본 프로젝트는 다양한 음성인식 API들의 성능을 객관적으로 평가하기 위해 공개되었습니다. 현재 시장에서 제공되는 다양한 음성인식 서비스의 성능 차이를 분석하고, 이를 통해 사용자와 개발자에게 더 나은 접근성을 제공하고자 합니다.
논문으로 공개되는 자료들은 보통 영어에 대해서만 성능 평가를 하고 WER(Word Error Rate)을 paperswithcode에 공개를 합니다. 하지만 한국어 음성인식은 WER이 아닌 CER(Character Error Rate)로 평가되어야 적절한데 잘 정리된 리더보드를 찾아볼 수가 없었습니다.
KsponSpeech가 2018년에 첫 공개되었지만, AI-Hub에 내국인만 접근 가능하고 음성인식을 연구하고 개발하는 한국인들이 적은 탓에 다양한 리소스로 공개되지 못했습니다.
리턴제로는 음성인식을 자체적으로 연구 개발하면서 이러한 리소스를 많은 사람들이 접할 수 있도록, KsponSpeech를 음성인식 분야에서 많이 쓰이는 speechbrain에 기여하여 현재 최신 recipe에서 사용해 볼 수 있고, huggingface에서도 접근할 수 있도록 기여하였습니다.
최근에는 다양한 종류의 음성 데이터들이 AI-Hub에 공개되었고, 이러한 다양한 데이터 세트에 대하여 한국어 음성인식 엔진이 어디까지 왔는지 평가해보고 알리는 것이 한국어 음성인식의 발전에 도움이 된다고 생각했습니다.
왜 CER로 계산하나요? (Character Error Rate)
WER(Word Error Rate)과 CER(Character Error Rate)의 계산 방법은 거의 동일합니다. 띄어쓰기로 구분되는 토큰들의 총개수에 대비되는 insertion, deletion, substitution의 수가 얼마나 많은지를 계산하는 것입니다. 차이가 있다면 WER은 단어가 토큰이 되며, CER은 문자가 토큰이 되는 것입니다.
동일한 수식으로 나타낼 수 있지만 어떤 단위(tokenizer)로 계산할 것인가의 차이입니다.
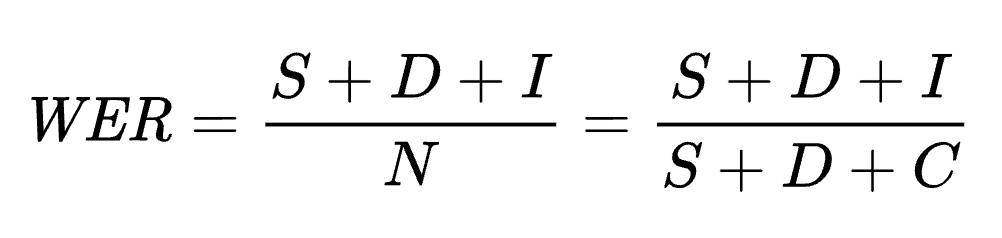
궁금한 문장을 직접 웹에 넣어 보실 수도 있습니다.
이를 계산하는 라이브러리는 다양한 언어별로 존재합니다.
- fastest-levenshtein: Javascript / Typescript
- Jiwer: Python
- Speechbrain: Python
- Go levenshitein: Go
한국어 특성에 따른 문제
한국어 음성인식에서는 WER 보다 CER이 더 중요한 척도로 여겨집니다. 한국어는 교착어(첨가어)로 조사를 사용하고 다른 언어와 비교하여 형태소의 구조가 복잡하며, 단어와 단어 사이의 경계가 모호합니다. 이러한 언어 구조의 특성으로 인해 단어 수준에서의 평가가 어렵습니다. 따라서, 문자 단위의 오류를 측정하는 CER이 한국어 음성인식에서 더 정확한 평가 방법으로 간주됩니다.
단어 수준의 오류 측정이 어려운 예시
| 번호 | 원문 | 인식 결과 | WER | CER |
|---|---|---|---|---|
| 1 | 나는 오늘 학교에 갔다 | 나는 오늘 학교 갔다 | 25% | 11.11% |
| 2 | 커피 한 잔 주세요 | 커피 한잔 주세요 | 50% | 0% |
| 3 | 어제 비가 왔어요 | 어제 비 왔어요 | 33.33% | 14.27% |
| 4 | 빨리 집에 가고 싶어 | 빨리 집에 가고싶어 | 50% | 0% |
위를 시각화 해보면 아래와 같이 🟨 칸에 인식결과에서 누락된 글자를 diff 로 볼 수 있습니다.
어제 비가 왔어요
어제 비🟨 왔어요
나는 오늘 학교에 갔다
나는 오늘 학교🟨 갔다
전사 데이터 정규화(Normalization)
2018년에 KsponSpeech가 공개될 때만 해도 음성인식 데이터가 많이 부족했는데 지금은 다양한 도메인, 다양한 목적을 가진 음성인식 데이터가 많이 공개되었습니다.
하나의 회사가 모든 데이터를 만들지 않기 때문에 만든 회사마다 데이터셋의 정규화(normalization)가 모두 다르게 되어있는데요. 어떤 회사는 잡음을 (NO:) 로 표기하기도 하고 어떤 회사는 /(noise) 로 표기 하기도 합니다. 또 어떤 회사는 웃음을 (SN:) 으로 표기하기도 하고 어떤 회사는 @웃음 으로 표기 하기도 합니다. 이처럼 데이터셋마다 다르게 되어 있는 normalization을 잘 전처리 해야 좋은 음성인식 모델을 만들 수 있습니다.
대부분의 데이터셋은 아래와 같이 발음과 철자를 모두 표기하는 이중 전사로 되어 있습니다.
(7시)/(일곱시),(ARS)/(에이 알 에스),(16 %)/(십 육 프로),(컴퓨터)/(컴터)
어떠한 전사 데이터를 사용하느냐에 따라 tokenizer의 vocabulary가 많이 달라지게 됩니다. 철자 전사로 학습 데이터를 구성 했다면 한글 뿐만 아니라 숫자, 영어, 특수기호도 모두 vocabulary에 포함되지만 발음 전사로 학습 데이터를 구성 했다면 한글과 특수기호만 vocabulary로 사용하게 됩니다. OpenAI Whisper와 Google의 API는 전사 결과를 철자 전사로 출력하기 때문에 AI-Hub 데이터셋 중 철자전사로 이루어진 것들 위주로 뽑아서 테스트를 진행하였습니다.
한국어 데이터셋에 덧붙여
AI-Hub의 데이터셋은 학습(training)과 검증(validation) 세트로 나뉩니다.
데이터셋에 대한 자세한 통계와 자료는 해당 데이터셋을 클릭하면 AI-Hub으로 이동하여 확인할 수 있습니다.
| 데이터셋 | 화자 구성 | 평균 음성 길이 |
평균 글자수 |
요약 설명 |
|---|---|---|---|---|
| 주요 영역별 회의 음성 (v1.1) | 대화 (3인 이상) |
4.18 | 32.24 | 시사토론, 독서모임, 온라인회의, 방송에서의 자연스러운 환경과 잡음이 결합된 회의 형태의 발성 |
| 회의 음성 (v1.0) | 대화 (3인 이상) |
6.39 | 46.08 | 3인 이상 EBS 토론/토크 콘텐츠로 오디오당 20~40분 내외 |
| 상담 음성 (v1.2) | 대화(2인) | 4.70 | 36.11 | 콜센터(교육, 금융, 통신판매 도메인) |
| 저음질 전화망 음성 (v1.1) | 대화(2인) | 4.58 | 28.14 | 음질이 낮은 전화망에서 다양한 잡음을 포함한 음성 |
| 한국어 강의 음성 (v1.1) | 강의(주로 1인) | 4.69 | 31.83 | 주제별, 수준별 학습 목적에 적합한 한국교육방송공사(EBS) TV/라디오 방송콘텐츠 및 온라인 강의 콘텐츠 |
| 한국어 음성 (KsponSpeech eval clean) (v1.0) |
대화(2인) | 3.17 | 21.52 | 두 사람이 다양한 주제로 자유롭게 대화하는 음성을 녹음하고 발성내용을 ERTI 전사규칙에 따라 철자전사 |
| 한국어 음성 (KsponSpeech eval other) (v1.0) |
대화(2인) | 4.56 | 30.62 | 두 사람이 다양한 주제로 자유롭게 대화하는 음성을 녹음하고 발성내용을 ERTI 전사규칙에 따라 철자전사 |
Contribution
본 프로젝트에 기여하고 싶은 경우, Issue를 만들고 Pull Request를 만들어주세요.
e-mail: research@rtzr.ai
![[고객 사례] 일본어 AICC의 엔진이 구글에서 리턴제로 STT로 바뀐 이유](https://storage.ghost.io/c/0c/cc/0ccc5c74-75ff-4417-b280-0b6bddd19a54/content/images/size/w30/2023/08/---------aicc.png)
![[고객 사례] 광주광역시 소방안전본부 AI 기반 119 신고접수시스템 도입 사례](https://storage.ghost.io/c/0c/cc/0ccc5c74-75ff-4417-b280-0b6bddd19a54/content/images/size/w30/2023/08/----------.png)
