
by Troye
이번 튜토리얼에서는 Triton Inference Server에 요청하기 위해 필요한 복잡한 과정을 크게 줄인 리턴제로의 Tritony 라이브러리를 소개하겠습니다. 또 기본 Client와 Tritony를 이용해서 각각 Voice Activity Detection(이하 VAD) 모델에 요청하는 작업을 비교하겠습니다.
Triton Inference Server
Triton Inference Server는 NVIDIA에서 개발한 고성능의 추론을 위한 오픈 소스 소프트웨어입니다. CPU, GPU 자원의 효율적인 사용과 다양한 딥러닝 프레임워크를 지원합니다. 또한 모델 배포와 버전관리가 용이하고, 간편하게 Multi GPU 설정이 가능합니다. 그렇기에 Triton Inference Server를 이용한다면, 딥러닝 모델 배포를 위한 복잡한 과정을 간소화할 수 있습니다.
아래는 Triton Inference Server가 제공하는 주요 기능들입니다.
- 모델 동시 실행
- 다이나믹 배칭
- HTTP/REST, GRPC 프로토콜 지원
- C API, Java API 지원
- 다양한 딥러닝 프레임워크 지원(PyTorch, TensorFlow, ONNX, TensorRT 등)
- Ensembling, Business Logic Scripting을 이용한 모델 파이프라인 제공
- Model 평가 및 Metric(GPU Utilization, Throughput, Latency 등) 제공
Triton Client
Triton Inference Server로 배포된 모델에 요청을 보내기 위해선, Triton Client 라이브러리를 사용해야 합니다.
Triton Client는 다양한 언어의 API와 프로토콜을 지원하지만, 이번 튜토리얼에서는 Python과 GRPC를 이용하겠습니다. 더 다양한 Triton Client의 사용법이 궁금하시면, [링크]에서 확인할 수 있습니다.
이번 튜토리얼을 진행하기 위해서는 pydub , tritonclient, tritony 라이브러리가 필요합니다. 제공되는 샘플 코드를 받고, 아래의 명령어를 통해 라이브러리 설치를 진행해 주세요.
pip install -r requirements.txt
GRPC
Python GRPC Client의 간단한 예시로 설명을 이어가겠습니다.
GRPC 는 클라이언트에서 생성된 “Stub”이라는 인터페이스를 이용해서 통신을 수행합니다. Stub을 만들기 위해선, 먼저 요청을 보낼 주소를 이용해 “Channel”을 만들어야 합니다. 그리고 만들어진 Channel로 Stub의 생성을 완료합니다. 이제 생성된 Stub이 서버에 요청하는 데 사용됩니다.
이 과정은 다음과 같습니다.
import grpc
from tritonclient.grpc import service_pb2, service_pb2_grpc
url = "YOUR_GRPC_URL"
channel = grpc.insecure_channel(url)
grpc_stub = service_pb2_grpc.GRPCInferenceServiceStub(channel)
GRPC를 통해서 요청하는 과정은 대부분 아래의 순서를 따릅니다.
- 요청을 하기 위한 정보를 담은 request를 만듭니다.(request에 필요한 정보가 있다면 포함합니다)
- Stub을 통해 request를 넘겨, 실제 요청을 수행합니다.
request = service_pb2.DoExampleRequest(keyword_arguments) # name, version etc..
response = grpc_stub.DoExample(request)
기존 방식의 불편한 점
- 요청을 위한 Request를 각각 만들어야 합니다.
- 또한 Request에 필요한 파라미터의 이름을 알기 위해선, 복잡한 과정을 거쳐야 합니다.
따라서 실제 추론 요청을 진행하기 위한 전체 코드가 길고, 복잡해집니다.
Tritony
기존 GRPC Client의 불편한 점을 해결하고자, 리턴제로는 Tritony 라이브러리를 개발했습니다. 한 번의 설정으로 간단하게 Triton Sever에 추론요청을 할 수 있습니다.
Tritony 라이브러리의 사용법은 다음과 같습니다.
InferenceClient.create_with()함수를 이용해서, 추론을 진행할 모델에 대한 Client를 생성합니다.- 생성된 Client를 이용해서 서버에 추론을 요청합니다.
from tritony import InferenceClient
model_name = "MODEL_NAME"
version = "1"
url = "YOUR_GRPC_URL"
input_name = "INPUT_NAME"
client = InferenceClient.create_with(
model=model_name,
model_version=version,
url=url,
protocol="grpc")
inputs = [ ] # list[np.ndarray]
response = client({input_name: inputs})
이제 기본 Triton Client와 Tritony를 이용해서 Triton Server에 VAD 요청을 진행하겠습니다.
VAD
Voice Activity Detection(VAD)는 입력된 음성의 특정 구간에서 발화여부를 판단하는 작업입니다. 화자분리를 위한 과정 중 가장 먼저 수행되는 중요한 작업입니다.
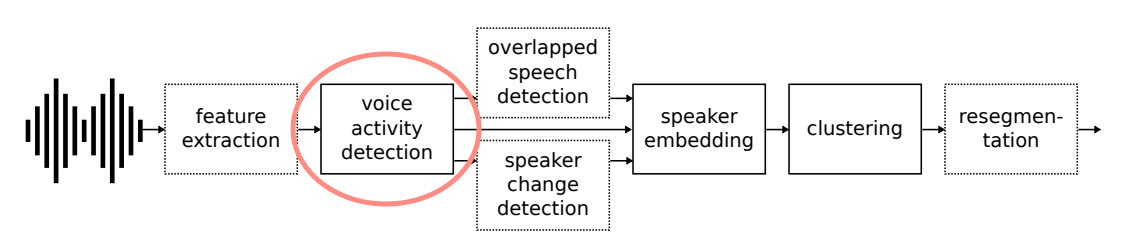
pyannote.audio
pyannote.audio 는 PyTorch 프레임워크로 화자 분리(Speaker Diarization)를 위해 작성된 오픈 소스 툴킷입니다. 화자 분리 진행 과정에 사용되는 Voice Activity Detection, Speaker Change Detection, Overlapped Speech Detection, Speaker Embedding 등 다양한 작업을 위한 파이프라인을 제공합니다.
이번 튜토리얼에서는 VAD 작업을 위해 pyannote.audio 라이브러리를 이용하겠습니다.
클라이언트 예시
저희는 VAD 작업을 위해 클라이언트를 이용해서 요청을 수행하고, 코드를 각각 비교해 보겠습니다. 작업 수행을 위한 Triton Server의 샘플은 제공됩니다.
샘플모델의 설정은 아래와 같습니다.
- model name :
python_vad - version :
1 - input name :
INPUT_0(float32) - output name :
OUTPUT_0(float32)
pydub 라이브러리가 이용됩니다.Triton Client
import os
import grpc
import argparse
import numpy as np
from pydub import AudioSegment
from tritonclient.grpc import service_pb2, service_pb2_grpc
from tritonclient.utils import triton_to_np_dtype
def load_wave(file_path, np_dtype=np.float32):
waveform = AudioSegment.from_wav(file_path)
waveform = waveform.set_frame_rate(16000).set_channels(1).get_array_of_samples()
np_waveform = np.array(waveform).astype(np_dtype)
np_waveform /= np.iinfo(waveform.typecode).max
return np_waveform
url = "0.0.0.0:8101"
model_name = "python_vad"
model_version = "1"
audio_path = "YOUR_AUDIO_PATH"
if __name__ == "__main__":
# Create a gRPC client for communicating with the server
channel = grpc.insecure_channel(url)
grpc_stub = service_pb2_grpc.GRPCInferenceServiceStub(channel)
# Get model metadata
model_metadata_request = service_pb2.ModelMetadataRequest(
name=model_name, version=model_version
)
model_metadata = grpc_stub.ModelMetadata(model_metadata_request)
input_name = model_metadata.inputs[0].name
output_name = model_metadata.outputs[0].name
input_dtype = model_metadata.inputs[0].datatype
output_dtype = model_metadata.outputs[0].datatype
# Prepare request
request = service_pb2.ModelInferRequest(
model_name=model_name, model_version=model_version
)
# Load Wave file to numpy array
np_waveform = load_wave(audio_path, triton_to_np_dtype(input_dtype)) # audio file(.wav) to mono, 16kHz Numpy array(raw data)
# Prepare input
input_tensor = service_pb2.ModelInferRequest().InferInputTensor(
name=input_name, datatype=input_dtype, shape=[len(np_waveform)]
)
# Set input data
request.inputs.extend([input_tensor])
# Prepare output
output_tensor = service_pb2.ModelInferRequest().InferRequestedOutputTensor(
name=output_name
)
# Set output data
request.outputs.extend([output_tensor])
# Set raw input data
request.raw_input_contents.extend(
[np_waveform.tobytes()]
)
# Send request
try:
response = grpc_stub.ModelInfer(request)
except Exception as e:
print(f"Request failed: {e}")
exit(1)
# Get output
response = np.frombuffer(
response.raw_output_contents[0],
dtype=triton_to_np_dtype(output_dtype)
) # Convert bytes to numpy array
- 서버에 요청을 보내기 위해 채널을 만들고, GRPC의 Stub을 생성합니다.
- 추론을 위한 request를 만들고, 입력과 출력의 정보를 가진 InputTensor와 OutputTensor를 추가합니다.
⋇ 모델의 입력이나 출력이 여러 개라면, 정보에 맞춰서 Tensor를 여러 개 추가해야 합니다. - 그 후 실제 추론을 위한 Raw Data를 추가해 줍니다.
- 마지막으로 Stub을 이용해서, 서버에 추론요청을 진행합니다.
- 추론의 결과로 넘어온
response도 Raw Data이기 때문에 다시 Numpy Array로 로드합니다.
Tritony
import os
import argparse
import numpy as np
from pydub import AudioSegment
from tritony import InferenceClient
from tritonclient.utils import triton_to_np_dtype
def load_wave(file_path, np_dtype=np.float32):
waveform = AudioSegment.from_wav(file_path)
waveform = waveform.set_frame_rate(16000).set_channels(1).get_array_of_samples()
np_waveform = np.array(waveform).astype(np_dtype)
np_waveform /= np.iinfo(waveform.typecode).max
return np_waveform
url = "0.0.0.0:8101"
model_name = "python_vad"
model_version = "1"
audio_path = "YOUR_AUDIO_PATH"
if __name__ == "__main__":
# Create a tritony gRPC client
client = InferenceClient.create_with(
model=model_name,
model_version=model_version,
url=url,
protocol="grpc",
run_async=False,
)
# Get model metadata
model_spec = client.model_specs[(model_name, model_version)]
model_input_name = model_spec.model_input[0].name
model_input_dtype = model_spec.model_input[0].dtype
# Prepare request
requests = []
np_waveform = load_wave(file_path=audio_path, np_dtype=triton_to_np_dtype(model_input_dtype))
requests.append(np_waveform)
response = client({model_input_name: requests})
- 사용할 모델의 이름과 버전, 서버의 주소, 프로토콜, 비동기 수행 여부를 제공해서 추론에 사용할 Client를 만듭니다.
requests에 추론에 사용할 입력데이터를 추가합니다.- 모델의 입력변수명(
model_input_name)에 대한 값을 넘겨주어, 추론을 요청합니다.
정리
기본 Triton Client 라이브러리와 Tritony를 이용해서 Triton Server에 추론요청을 보내는 과정을 비교했습니다. 두 라이브러리 모두 Triton Server의 음성파일을 입력으로 VAD 모델에 추론요청 하는 것은 동일합니다. 하지만 두 코드의 길이차이를 보면 알 수 있듯이 기본 Triton Client가 추론요청을 하기 위해서 더 복잡한 과정을 거쳐야 한다는 것을 확인을 할 수 있습니다.
Tritony는 개발자가 Triton Server에 추론 요청을 위해 필요한 과정을 간소화하여 딥러닝 모델을 더 편리하게 이용할 수 있도록 개발되었습니다.
전체 예시 코드
https://github.com/vito-ai/python-tutorial/tree/main/tritony-sample
 vito-ai
vito-ai참조
[Image 1] : https://arxiv.org/pdf/1911.01255.pdf


