
by Kaveh
리턴제로는 Developers 사이트에서 우수한 음성인식(STT) API를 사용하는 방법을 제공하며, 이를 사용하는 방법은 아주 간단합니다. 이번 튜토리얼에서는 리턴제로의 API를 사용하여 Python만으로 음성변환 및 요약 웹앱을 만들어보겠습니다.
이 튜토리얼의 코드는 모두 Ubuntu 22.04.3 LTS에서 작성하였으며, python 3.8 이상에서 호환 가능합니다.
0. STT API 사용을 위한 토큰 발급
리턴제로의 STT API를 사용하기 위해서, 먼저 아래의 Developers 사이트에 회원가입을 해야합니다.

https:/developers.rtzr.ai/signup
회원가입을 하고 로그인을 한 다음 아래의 링크로 접속한 뒤 콘솔에 접근합니다.
https://developers.rtzr.ai/dashboard
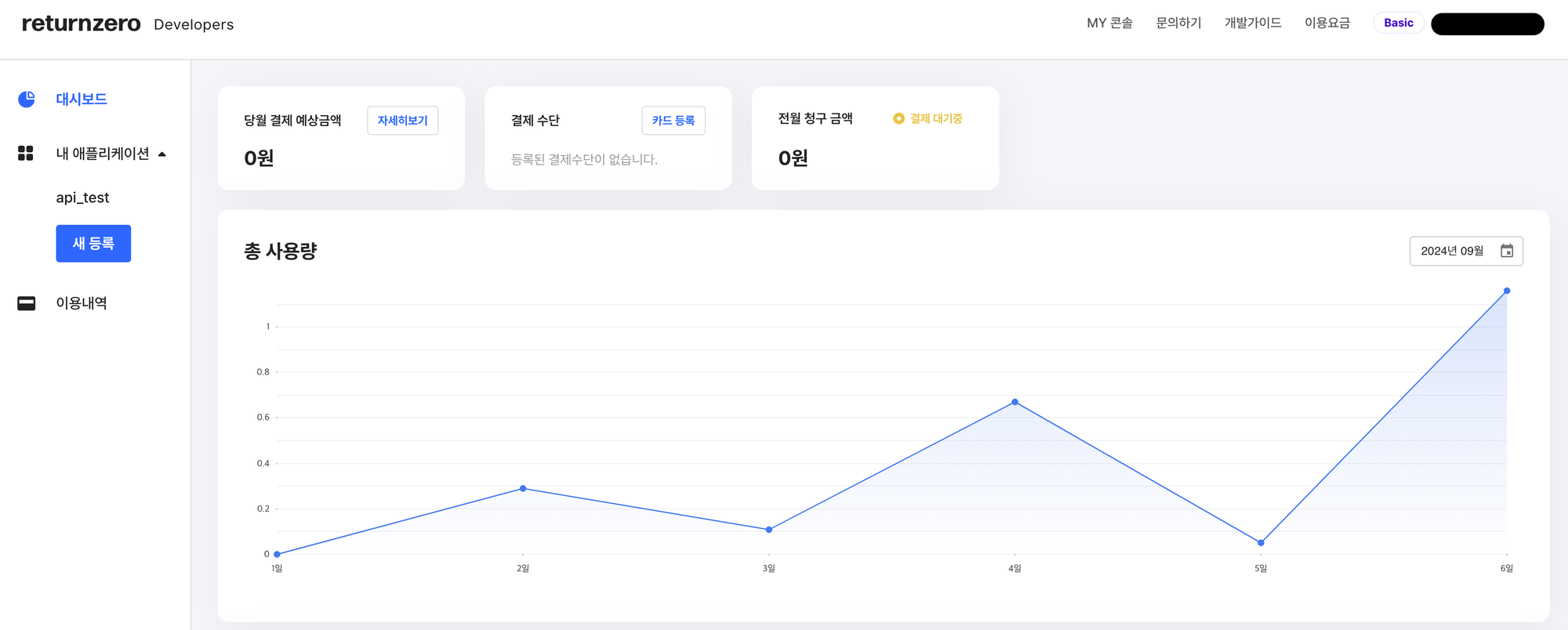
콘솔에 접근하면 아래의 화면이 보입니다. 여기서 내 애플리케이션→새 등록을 눌러 애플리케이션을 추가해줍니다.
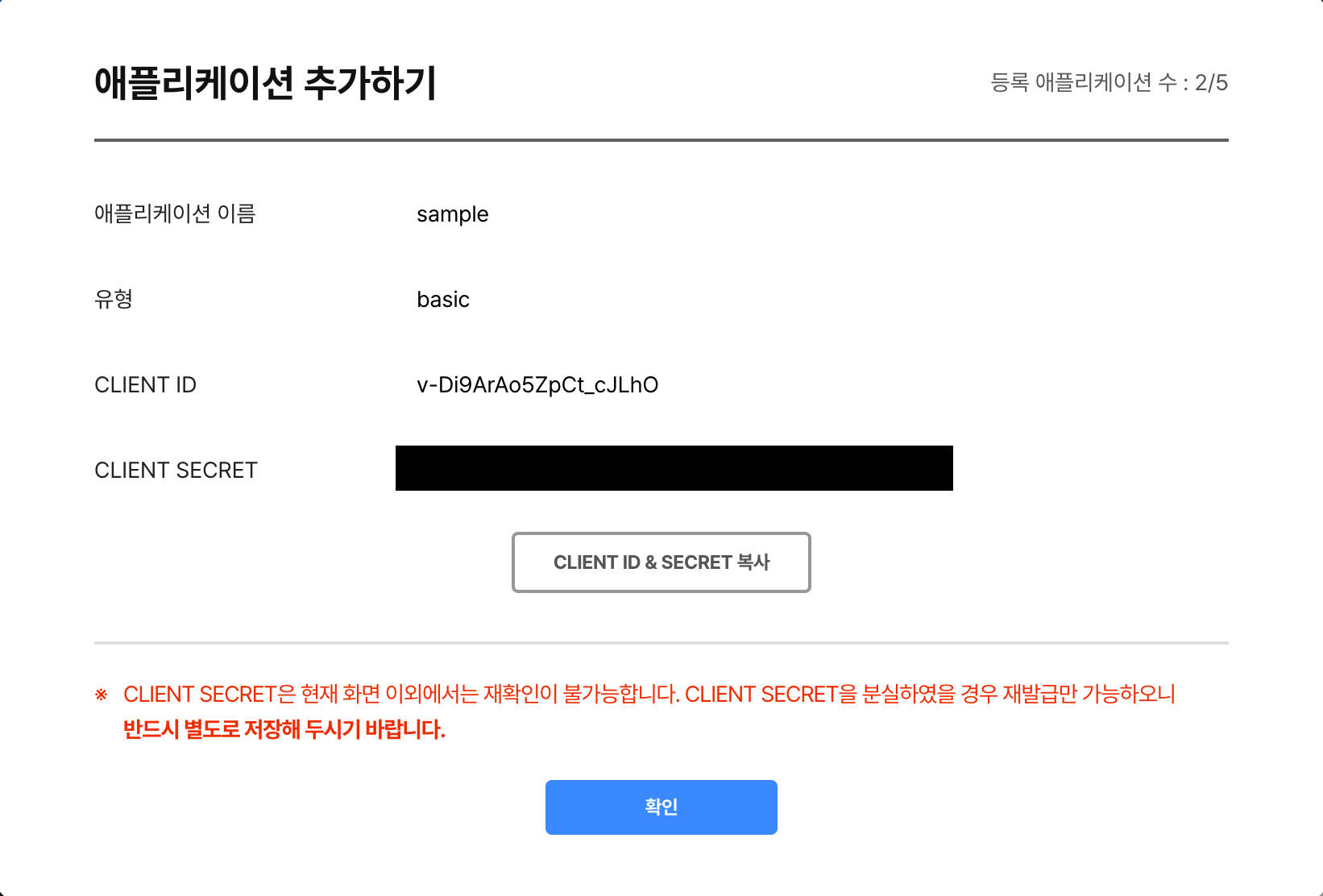
이후 아래처럼 CLIENT ID와 CLIENT SECRET 발급될텐데, 분실 시 재발급이 어려우니 별도로 저장해주세요!
1. VITO API 소개와 파일 구조 및 라이브러리 소개
VITO STT API 소개
또한 리턴제로의 API는 Developers docs 페이지를 통해 빠르고 쉽게 학습할 수 있으며, 아래의 기능처럼 다양한 API를 사용할 수 있습니다.
- 영어, 숫자, 단위에 해당하는 표현을 한글이 아닌 가독성 높은 표기로 변환할 수 있습니다.
- 예를 들어 ‘이천이십사년 구월 육일에는 비가 내릴 예정입니다.’를 ‘2024년 9월 6일에는 비가 내릴 예정입니다.’처럼 변경해주는 기능입니다.
- 두 명 이상의 화자 분리를 편하고 빠르게 구현할 수 있습니다.
- 이 기능을 통해 누가, 언제, 어떤 이야기를 했는지에 대한 정보를 파악할 수 있습니다.
- 비속어를 간단하게 필터링 할 수 있습니다.
- 특별한 정보가 없는 욕설에만 한정되며, 성적/종교/인정 관련 차별이나 혐오는 정보를 지니고 있기에 필터링되지 않습니다.
- '어…', '음…', '네네네'와 같이 발화에서 큰 의미가 없거나 중복 표현되는 발화를 쉽게 제거할 수 있습니다.
- 예를 들어, ‘음.. 네네 알겠습니다’ 같은 표현을 ‘네 알겠습니다.’처럼 간결한 텍스트를 제공할 수 있습니다.
- 문장이 아닌 단어별로 timestamp 정보를 받을 수 있습니다.
- 키워드 부스팅 기능을 통하여 중요한 단어와 다소 중요도가 떨어지는 문장의 정확도를 설정할 수 있습니다.
- 이 기능은 한글만 지원합니다.
- 특정 도메인에 특화되는 모델을 제공하는 기능입니다.
- 현재는 일반적인 음성 모델과 통화 녹음에 특화된 모델을 제공합니다.
이번 튜토리얼에서는 도메인 특화 기능, 다화자 인식 기능, 욕설 필터링, 키워드 부스팅을 사용합니다.
파일 구조 소개
프로젝트의 주요 파일 구조는 다음과 같습니다.
└── 업로드된 음성 파일들(inference 후 삭제)
src/
└── main.py
└── model.py
└── utils.py
main.py: 실행 파일model.py: RTZR API 및 요약 모델 관련 클래스를 정의한 파일utils.py: 유틸리티 함수들과 메인 페이지를 구성하는 함수가 포함되어 있는 파일
라이브러리 소개
아래의 라이브러리를 사용하였으며, python 버전 3.8 이상부터 호환됩니다.
아래 라이브러리들은 pip install -r requirements.txt 명령어로 설치할 수 있습니다.
*로컬 환경에서 streamlit 라이브러리 첫 사용 시 터미널에서 이메일을 입력해야할 수도 있습니다.
- Streamlit : 데이터 애플리케이션을 위한 오픈소스 프레임워크 라이브러리
- Requests : HTTP 요청을 쉽게 보낼 수 있는 라이브러리
- Torch : 딥러닝을 위한 오픈소스 딥러닝 라이브러리
- Transformers : 자연어 처리 task를 위한 최신 모델들을 제공하는 라이브러리(huggingface 제공)
Streamlit을 통하여 웹을 디자인하고, 리턴제로의 API와 transformers 라이브러리를 통해 모델을 구축합니다.
Hugging Face 모델 소개
Hugging Face는 전세계 사람들이 만든 인공지능 모델들을 손쉽게 사용할 수 있는 라이브러리로, 본 튜토리얼에서는 ‘EbanLee/kobart-summary-v3’ 모델을 사용하였습니다.
이 모델은 한국어 뉴스 텍스트 요약에 특화된 모델로 다른 언어나 다른 도메인의 모델을 사용하고 싶으신 경우, 허깅페이스 모델 페이지에서 찾아서 사용하실 수 있습니다.
2. model.py
model.py 파일에는 리턴제로의 API를 사용하는 RtzrAPI 클래스와 클래스를 이루는 메소드들로 구성되어 있습니다.
먼저, RtzrAPI 클래스의 __init__ 메소드에서는, 리턴제로의 API를 사용하기 위해 client_id나 client_sceret 및 file_path 등과 같이 필요한 정보들을 초기화 합니다.
이후에 사용자 인증을 하는 auth_check와 서버에 데이터를 요청하는 api_post 메소드를 실행하여 리턴제로의 API를 사용합니다.
def __init__(
self,
client_id: str,
client_sceret: str,
dev: bool,
file_path: dict,
speaker_num: int,
domain: str,
profanity_filter: bool,
keyword: list,
) -> None:
"""api 사용에 필요한 인자 초기화"""
self.dev: str = "dev-" if dev else ""
self.client_id: str = client_id
self.client_sceret: str = client_sceret
self.file_path: dict = file_path
self.speaker_num: int = speaker_num
self.config: dict = (
{"domain": "GENERAL"} if domain == "일반" else {"domain": "CALL"}
)
if speaker_num != 0:
self.config["use_diarization"] = True
self.config["diarization"] = {"spk_count": speaker_num}
if profanity_filter:
self.config["use_profanity_filter"] = True
if keyword:
self.config["keyword"] = keyword
self.raw_data: json = None
self.voice_data: str = None
self.summary_data: str = None
self.access_token: str = self.auth_check(client_id, client_sceret)
self.transcribe_id: str = self.api_post(self.access_token)
auth_check 메소드는 __init__에서 인자로 받았던 client_id와 client_sceret을 사용하여, API를 사용하기 위한 access_token을 발급받은 뒤 access_token을 반환합니다.
def auth_check(self, client_id: str, client_sceret: str) -> str:
resp = requests.post(
f"https://{self.dev}openapi.vito.ai/v1/authenticate",
data={"client_id": client_id, "client_secret": client_sceret},
)
resp.raise_for_status()
return resp.json()["access_token"]
이후, auth_check에서 발급받은 access_token을 사용하여 api_post메소드에서 오디오 파일 텍스트 변환을 서버에 요청하고, 요청한 id를 반환합니다.
업로드한 파일을 전사하는 시간이 있어, POST를 통해 파일을 전송한 후 GET요청을 하기까지 조금 기다려야합니다. 이 때, 기다리지 않고 바로 GET요청을 하면 제대로된 결과가 나오지 않습니다.
def api_post(self, access_token: str) -> None:
"""access_token을 인자로 받고 api요청을 하는 메소드. Get에 필요한 transcribe_id 리턴"""
resp = requests.post(
f"https://{self.dev}openapi.vito.ai/v1/transcribe",
headers={"Authorization": f"Bearer {access_token}"},
files=self.file_path,
data={"config": json.dumps(self.config)},
)
resp.raise_for_status()
return resp.json()["id"]
마지막으로, api_get메소드에서 api_post에서 반환받은 id를 통해 텍스트로 변환된 데이터를 받습니다.
텍스트 데이터를 화자의 수에 따라 전처리 해주는 메소드 preprocessing를 호출해줍니다.
def api_get(
self,
) -> None:
"""텍스트로 변환된 값을 받는 메소드"""
resp = requests.get(
f"https://{self.dev}openapi.vito.ai/v1/transcribe/" + self.transcribe_id,
headers={"Authorization": "bearer " + self.access_token},
)
resp.raise_for_status()
if resp.json()["status"] == "transcribing":
self.raw_data = None
else:
self.raw_data = resp.json()
self.voice_data = self.preprocessing(self.raw_data)
preprocessing 메소드에서는 화자의 수에 따라서 텍스트를 다르게 변환해줍니다.
화자수가 2명 이상일 때는 문장 앞에 ‘화자N ]’이 붙습니다.
def preprocessing(self, raw_data: dict) -> str:
"""
텍스트를 전처리 하는 메소드
화자가 두 명 이상일 경우 speaker n] text... 형태로 출력
"""
if len(set([x["spk"] for x in raw_data["results"]["utterances"]])) == 1:
return " ".join([data["msg"] for data in raw_data["results"]["utterances"]])
else:
return " \\n".join(
[
f"화자{text_data['spk']} ] {text_data['msg']}"
for text_data in raw_data["results"]["utterances"]
]
)
summary_inference 메소드에서는 hugging face tokenizer와 model을 불러와 api_get에서 받은 데이터를 요약해주는 일을 합니다.
먼저, utils.py의 load_model메소드를 통해 호출한 hugging face의 모델과 토크나이저를 사용하여 인코딩해줍니다.
이후 데이터를 inference 해준 뒤, 디코딩해주어 요약을 완료합니다.
def summary_inference(
self,
) -> None:
"""hugging face 모델을 사용해 텍스트 내용을 요약해주는 메소드. 문장이 짧으면 'Text too short를 반환"""
if len(self.voice_data) < 40:
self.summary_data = "Text too short!!"
return None
# Encoding
inputs = tokenizer(
self.voice_data,
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=1026,
)
# Generate Summary Text
summary_text_ids = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
bos_token_id=model.config.bos_token_id,
eos_token_id=model.config.eos_token_id,
length_penalty=1.0,
max_length=300,
min_length=12,
num_beams=6,
repetition_penalty=1.5,
no_repeat_ngram_size=15,
)
# Decoding
self.summary_data = tokenizer.decode(
summary_text_ids[0], skip_special_tokens=True
)
model.py 파일을 요약하면 다음과 같습니다.
__init__메소드에서 API 호출에 필요한 메소드들을 초기화한다.auth_check메소드에서 API사용을 가능하게 하는 acces token을 발급한다.api_post메소드에서 오디오 파일의 텍스트 변환을 요청한다.api_get를 통해 3에서 요청한 값을 받아온다.summary_inference메소드에서 4에서 받은 값을 요약한다.
3. utils.py 코드 분석
load_model 함수는 hugging face의 모델을 불러오는 함수입니다. streamlit 내장 데코레이터을 사용하여, 여러번 모델을 호출하지 않게 설계하였으며 이를 통해 리소스 사용을 감소 시켰습니다.
@st.cache_resource() # cache사용해서 새로고침 시 리소스 절감
def load_model():
"""모델 불러오는 함수"""
model = BartForConditionalGeneration.from_pretrained("EbanLee/kobart-summary-v3")
tokenizer = PreTrainedTokenizerFast.from_pretrained("EbanLee/kobart-summary-v3")
return model, tokenizer
file_upload_save 함수는 streamlit의 내장함수인 uploadfile을 통해 업로드된 오디오 파일을 인자로 받고, 이를 저장하는 함수입니다. 인자로 받은 upload_file을 디렉토리에 저장하고, 해당 오디오 파일이 있는 경로를 반환합니다.
def file_upload_save(dir: str, upload_file: str) -> str:
"""업로드한 파일을 지정된 경로에 다운받고, 로컬 폴더의 경로를 반환하는 함수"""
try:
if not os.path.exists(dir):
os.mkdir(dir)
except OSError:
print("error")
if upload_file is not None:
bytes_data = upload_file.read()
with open(f"{dir}/{upload_file.name}", "wb") as file:
file.write(bytes_data)
path = Path(dir) / upload_file.name
return path
display_audio_file 함수에서는 streamlit의 내장함수인 audio를 사용하여 업로드된 음성파일을 실행합니다.
def display_audio_file(wavpath: str) -> None:
"""streamlit audio 재생"""
audio_bytes = open(wavpath, "rb").read()
file_type = Path(wavpath).suffix
st.audio(audio_bytes, format=f"audio/{file_type}", start_time=0)
page_setup에서는 메인 페이지의 구성들과 API 사용에 필요한 client_id, client_secret이나 파일 등과 같은 정보들을 입력할 수 있는 웹을 구성합니다.
def page_setup(logo_url: str, homepage_url: str, tutorial_url: str) -> st.file_uploader:
"""streamlit 메인페이지 구성 return은 음성 파일이 들어있는 my_upload"""
if "model" not in st.session_state:
with st.spinner("model and page loading..."):
st.session_state.model, st.session_state.tokenizer = load_model()
st.markdown(
f'[]({homepage_url}) <span style="font-size: 30px;">**Return Zero**</span>',
unsafe_allow_html=True,
)
st.header("음성 변환 및 요약 웹앱 Tutorial", divider="gray")
st.subheader("[API 키 발급 받으러 가기](%s)" % tutorial_url)
st.sidebar.write("## 아래를 채워주세요!(*는 필수)")
with st.sidebar.form("my-form", clear_on_submit=False):
st.checkbox("dev?", key="dev")
st.text_input(
"*Client Id를 작성해주세요👇", placeholder="client id", key="client_id"
)
st.text_input(
"*Client Secret을 작성해주세요👇",
placeholder="client secret",
key="client_secret",
)
my_upload = st.file_uploader(
"*오디오 파일을 업로드 해주세요",
type=["mp4", "m4a", "mp3", "amr", "flac", "wav"],
key="file",
)
st.radio("화자의 수는 몇 명인가요?", ["1", "2", "3", "4+"], key="speaker_num")
st.radio("도메인은 어떤 분야인가요?", ["일반", "전화통화"], key="domain")
st.checkbox("욕설 필터링을 할까요?", key="profanity_filter")
st.text_input(
"음성 인식에 중요한 키워드를 입력해주세요",
placeholder="대한민국, 일본, 중국",
key="boost_keyword",
)
st.form_submit_button("submit")
return my_upload
display_result에서는 page_setup 함수에서 받은 정보들을 이용해 API를 호출한 결과와 요약된 텍스트를 웹상에 출력합니다.
def display_result(audio_file_path: str, upload_file: st.file_uploader) -> None:
"""streamlit 결과 화면"""
if (
st.session_state.client_id
and st.session_state.client_secret
and st.session_state.file
):
# sound file download func
file_path: str = str(file_upload_save(audio_file_path, upload_file))
file: dict = {"file": (file_path, open(file_path, "rb"))}
speaker_num: int = (
0
if st.session_state.speaker_num == "4+"
else int(st.session_state.speaker_num)
)
# call RtzrAPI class
try:
api = RtzrAPI(
st.session_state.client_id,
st.session_state.client_secret,
st.session_state.dev,
file,
speaker_num,
st.session_state.domain,
st.session_state.profanity_filter,
st.session_state.boost_keyword.replace(" ", "").split(","),
)
with st.spinner("wait for it"):
while api.get_raw_data is None:
time.sleep(5)
api.api_get()
# inference
api.summary_inference()
# audio file display
display_audio_file(file_path)
# result print
col1, col2 = st.columns(2)
col1.markdown("## 음성 변환")
all_text_field = col1.container(border=True, height=400)
col2.markdown("## 음성 변환 요약")
summary_text_field = col2.container(border=True, height=400)
all_text_field.write_stream(stream_data(api.get_text_data))
summary_text_field.write_stream(stream_data(api.get_summary_data))
os.remove(file_path)
except Exception as e:
st.write(f"오류 발생: {str(e)}")
else:
st.markdown("<br><br>", unsafe_allow_html=True)
st.subheader("Client id, Client Secret, 변환할 파일을 올려주세요")
utils.py 를 요약하면 다음과 같습니다.
load_model: 모델을 불러온다.file_upload_save: 업로드된 오디오 파일을 저장한다.display_audio_file: 웹 앱에서 오디오 파일을 재생할 수 있게 해준다.page_setup: 메인 페이지 초기화 및 구성을 한다.display_result: 텍스트로 변환된 데이터와 요약된 데이터를 웹상에 출력시킨다.
4. main.py 코드 분석
main.py에서는 웹 구성에 사용되는 링크들과 directory path를 정의하고 streamlit의 초기설정을 세팅합니다. 이후, utils.py의 page_setup, display_result함수를 호출하여 웹을 구성합니다.
if __name__ == '__main__':
RTZR_LOGO_URL = "https://www.rtzr.ai/rtzr_logo.svg"
RTZR_HOMEPAGE_URL = "http://rtzr.ai"
API_TUTORIAL_URL = "https://developers.rtzr.ai/docs/authentications"
AUDIO_FILE_PATH = "./resource"
#streamlit setting
st.set_page_config(layout="wide", page_title="STT and Summary", page_icon = RTZR_LOGO_URL)
#streamlit main
with st.container():
my_upload:st.file_uploader = pageSetup(RTZR_LOGO_URL,RTZR_HOMEPAGE_URL,API_TUTORIAL_URL)
displayResult(AUDIO_FILE_PATH, my_upload)5. 최종 실행 결과 및 소스코드
- 이 애플리케이션을 로컬 환경에서 실행하기 위해, github를 통해 코드를 clone한 다음, 터미널에서 아래의 명령어를 사용하시면 됩니다.
아래의 명령어를 사용하기 위해, Python과 git이 필요합니다.
git clone https://github.com/vito-ai/python-tutorial.git
cd ./python-tutorial/streamlit-webapp
pip install - r requirements.txt
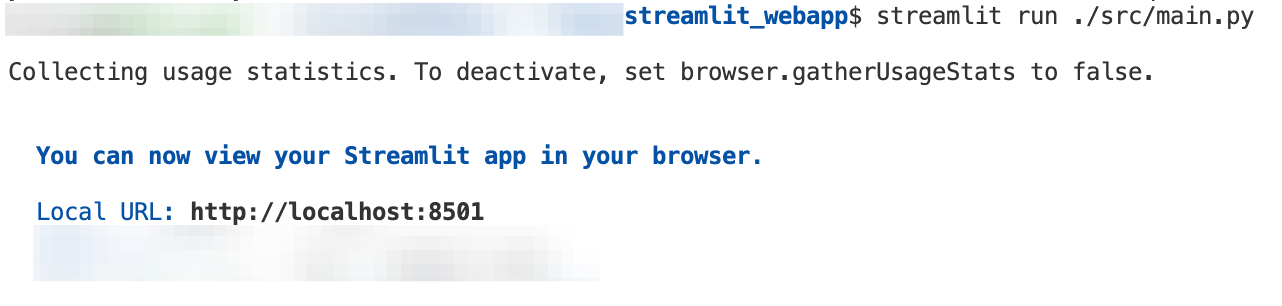
streamlit run ./src/main.py- 터미널 환경에서 위 명령어를 실행하면 아래와 같은 화면이 보입니다.
- http://localhost:8501 에 접속하여 애플리케이션을 사용하실 수 있습니다.
- 애플리케이션에 접속하시면 아래의 페이지가 나옵니다. 해당 페이지에서 '아래를 채워주세요!(*는 필수)' 필드를 채우고, submit 버튼을 누릅니다.

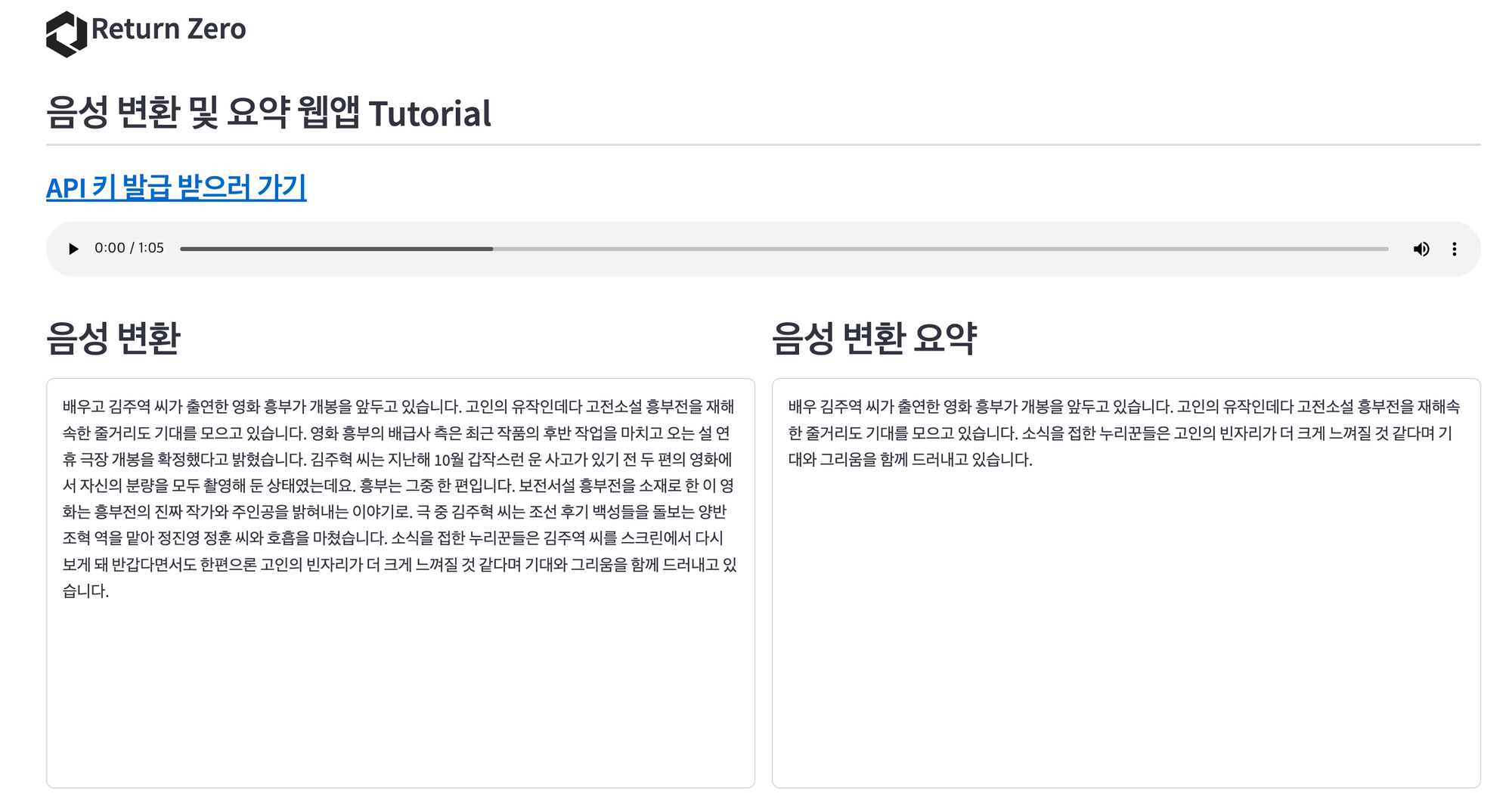
저는 아래의 샘플 데이터를 사용하여 웹앱을 실행하였습니다.
샘플 데이터를 사용한 결과는 아래와 같습니다. STT와 요약 모두 잘 작동하는 것을 볼 수 있습니다.

전체적인 코드는 아래를 참고하시면 됩니다.
https://github.com/vito-ai/python-tutorial/tree/main/streamlit-webapp
6. 마무리
이번 블로그는 Python의 streamlit과 리턴제로의 API만을 가지고, 프론트엔드와 백엔드에 대한 지식이 없어도 구현 가능한 웹앱을 만들어 보았습니다. 해당 웹앱에는 리턴제로의 API를 사용해서 파일 음성을 STT로 변환하고, 변환된 음성을 요약하는 기능을 구현하였습니다.
Python이나 Go와 같이 프로그래밍 언어에 친숙하지 않아도 개발자 가이드에 간단명료하게 사용법이 쓰여져 있기 때문에, 누구나 쉽고 빠르게 리턴제로의 STT API를 사용 가능합니다.
마지막으로, 오늘 블로그에서 웹앱을 구현한 것처럼 리턴제로의 API를 사용하여 다양한 서비스를 구현하실 수 있습니다. 예를 들어 유튜브 영상 자막을 자동으로 달아주는 웹앱을 만든다거나, 회의록을 STT로 전사하는 웹앱 등 STT가 필요한 어떤 Task든 다양하게 리턴제로의 API를 사용하실 수 있습니다.
긴 글 읽어주셔서 감사합니다.


